In a noisy conversation environment such as a dinner party, people often exhibit selective auditory attention, or the ability to focus on a particular speaker while tuning out others. Understanding who somebody is listening to in a conversation is essential for developing technologies that understand social behavior and devices that can augment human hearing by amplifying particular sound sources. The computer vision and audio research communities have made great strides towards recognizing sound sources and speakers in scenes. In this work, we take a step further by focusing on the problem of localizing auditory attention targets in egocentric video, or detecting who in a camera wearer's field of view they are listening to. To tackle the new and challenging Selective Auditory Attention Localization (SAAL) problem, we propose an end-to-end deep learning approach that uses egocentric video and multichannel audio to predict the heatmap of the camera wearer's auditory attention. Our approach leverages spatiotemporal audiovisual features and holistic reasoning about the scene to make predictions, and outperforms a set of baselines on a challenging multi-speaker conversation dataset.
Approach
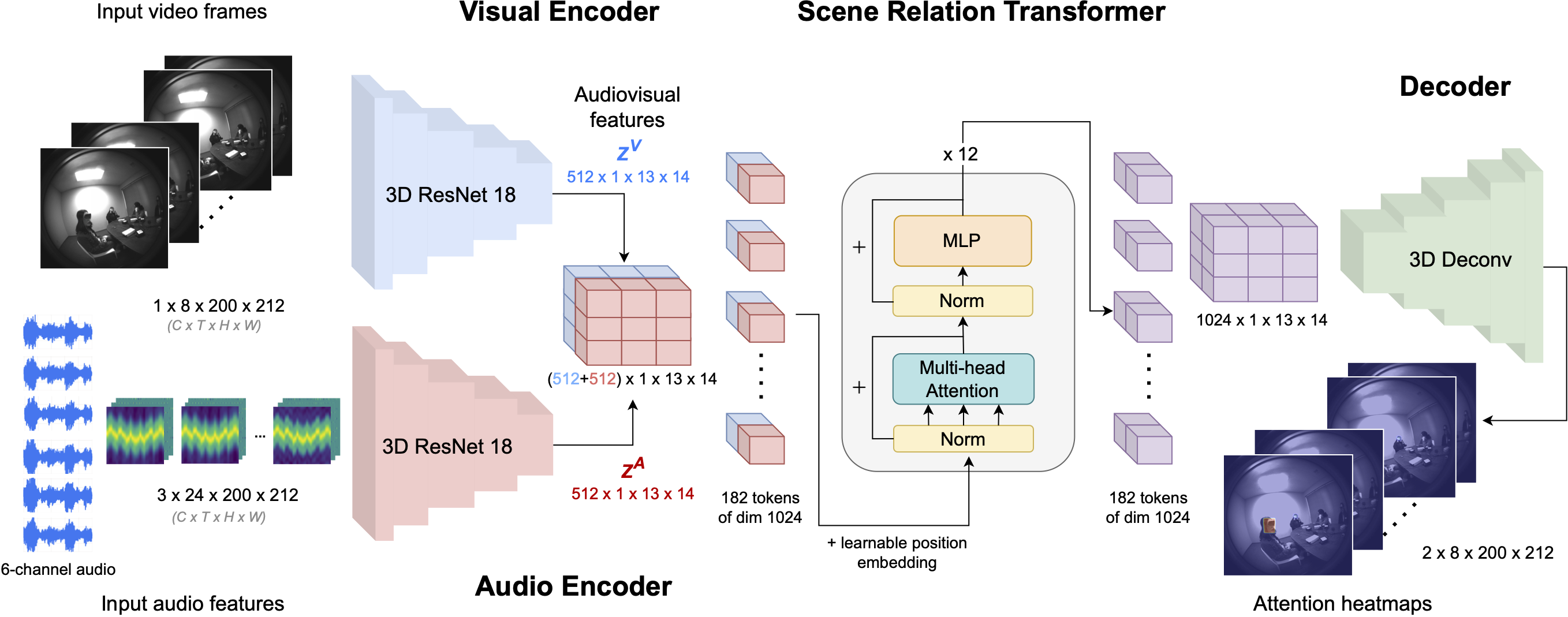
We propose a multimodal spatiotemporal architecture that takes in a video clip and its accompanying multichannel audio and predicts an auditory attention heatmap for each frame. Our model consists of 4 main components: the Video Encoder extracts visual and temporal information from the video like the locations of people and their body language; the Audio Encoder extracts a spatial representation of voice activity in the scene; the Scene Relation Transformer refines attention localization by reasoning about the audiovisual content across the full scene; and the Decoder produces an auditory attention heatmap for each frame.
Evaluation Dataset
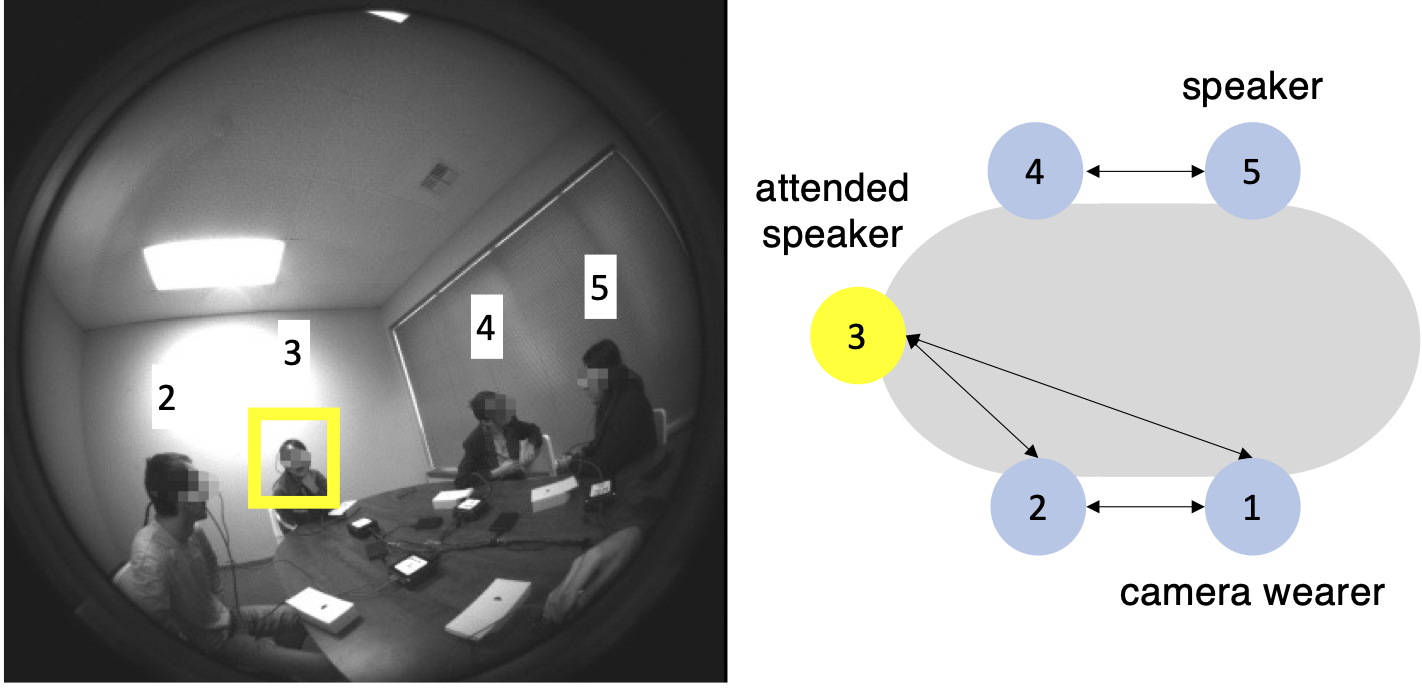
We specifically target complex conversation environments where there are multiple speakers present by designing a multi-speaker conversation dataset. In our dataset, 5 people are split into 2 conversation subgroups and are instructed to only listen within their own conversation subgroup. We therefore can determine auditory attention labels as who is both speaking and within the camera wearer's conversation subgroup. This allows us to obtain an objective measure for auditory attention, and everyday noisy environments like coffee shops, restaurants, parties, and large dinner tables.
Demo Videos
We show visualizations of our model's output on the test subset below. The predicted heatmaps are overlayed on the input video frames. Yellow bounding boxes show ground truth attended speakers, and blue bounding boxes show speakers who are not attended.
Citation
@inproceedings{ryan2023egocentric,
author = {Ryan, Fiona and Jiang, Hao and Shukla, Abhinav and Rehg, James M and Ithapu, Vamsi
Krishna},
title = {Egocentric Auditory Attention Localization in Conversations},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages = {14663--14674},
year = {2023}
}
Contact
For questions about this work, please contact fkryan at gatech dot edu.